
Santos Solorzano
Santos is a Software Engineer at Winnie.
Read about the technologies and data systems that brought Winnie's daycare and preschool marketplace to millions of parents across the US.
At Winnie, a marketplace to help parents find preschools, daycares, and more, we’re providing parents with the best tools to give them the information and support they need. Our product would not exist without the web frameworks and cloud services available today. On my quest to infiltrate the Internet with my technical presence, I wanted to share some of the technologies we use to build Winnie.

Note: we have an iOS app written in Swift and an Android app written in Kotlin. This article does not cover our mobile applications. If you have any questions, I’d be more than happy to forward them to our mobile engineers.
Application
Docker
Docker makes it easy to set up and deploy standardized development environments. The oft-used excuse, “it works on my computer”, is now a thing of the past. When I joined Winnie, I had everything I needed to start writing code as soon as I installed Docker and cloned the main repository.
Before deploying to production, engineers test their changes in staging and sandbox environments. Our staging environment has tons of cat data: cat day cares, cat photos, cat comments. You name it. It is safe to create, delete, and update this staging data — there are no ramifications. Our sandbox environment is a different beast. The data in sandbox is a subset of our production data. It’s helpful to see what our web application will look like with real data. Sooner than later, this is what users will see! We use this environment for final, final testing. Once we’re confident with the changes, they get merged and deployed.
Django
When you visit https://winnie.com/, you are interacting with a Django application. The framework has been fun to work with so far. The phrase, “batteries included,” has never been more true when applied to Django. You have everything you need to create a web application. HTML templating. URL routing. Session management. I still remember learning about the slugify()method when working on my first project. Can you imagine coming up with your own slugs? Or writing your own email validator? Since Django gives you all these things for free, you don’t have to concern yourself with reinventing the wheel. You can work on features that customers want or fix that thing you’ve pushed down the backlog for so long. Lastly, you can enhance your application by adding third-party packages such as email delivery and error tracking. We use SendGrid and Sentry.
Django also allows applications to register management commands (e.g. managing users via the command line). You can read more about management commands in this article. We leverage this interface to run one-off and recurring scripts. This has been very handy to us for setting up cron jobs. For example, we have a weekly cron job that generates and sends a digest email to all subscribed users. This personalized email includes posts and reviews posted on Winnie throughout the week.
AWS
DynamoDB
As a startup, we want the flexibility to test out new features with our semi-structured data. We can add attributes to database tables in DynamoDB without having to worry about a strict schema or migration scripts. Being on AWS is great because it allows the whole team to dabble in DevOps. Anyone can go into the AWS console and create table backups or update resource permissions. We can see metrics on each of our production tables and get insights on capacity usage, latency, and errors.
DynamoDB does come with its caveats. On top of the primary index, you can add secondary index on a table if you want to query by certain fields besides an id (e.g. created timestamp). There is also a limit to how many secondary indexes you can add per table. Creating a new index is costly and does not happen right away so you are out of luck if you are short on time and money. Since DynamoDB is a non-relational database, there is no support for joining tables. We have implemented some custom code in our applications to support “joining” tables. I don’t think our engineers would be opposed to using a relational database as our data becomes more structured over time.
Lambda
One feature we take advantage of is DynamoDB Streams. The stream captures additions, updates, and deletions for a table, and other services can read those events to do additional processes. We’ve chosen AWS Lambda as the consumer of these events to asynchronously handle various tasks, such as updating aggregate counts and re-indexing documents in our search clusters. We found AWS Lambda to be a quick and cheap way to handle simple tasks like these compared to running your own consumers on a dedicated EC2 instance.
Search
 The team at Winnie is upping up their search game!
The team at Winnie is upping up their search game!CloudSearch
Being on AWS, it made sense for us to use CloudSearch as our search technology. This made it easier for us to integrate with other services we were already using. CloudSearch was easy to set up and we had powerful search capabilities on Winnie right away. We have a lot of content indexed in CloudSearch. User comments, place reviews, but most importantly daycare and preschool information.
With over a million users in 10,000 cities across the United States, there is a plethora of information that parents can find on Winnie. Parents searching for child care can use our awesome child care discovery platform. Parents can search for and browse thousands of providers listed on Winnie. They can see detailed information on providers including licensing information, pricing, and hours. When parents search for child care, they can filter search results by availability, age, calendar type and facility type.
Note: we started off collecting detailed information for a couple of cities such as Los Angeles and Chicago. We’re currently expanding our efforts to include the rest of the country.
ElasticSearch (experimental)
We believe in using the right tool for the right job. The last known update to CloudSearch was made in 2015. Seeing as ElasticSearch was receiving frequent updates, we decided to pilot this technology for a project.
Less than a year ago, we made some changes to the feed users see when logging on. Instead of a chronological feed of posts and reviews, users now see content relevant to the topics they follow. Local content is also more prominent throughout the platform as an effort to engage the community more. We’ve been impressed with ElasticSearch and are considering migrating to it in the future. It wasn’t as easy to set up as CloudSearch but we are already reaping some of the benefits like support for more data types and being able to construct complex queries.
If you’ve ever wondered what it takes to build search functionality in to an application, you should check out either search engine. I’ve learned a lot of things such as faceted search, document batching, and paginating results.
Message queues
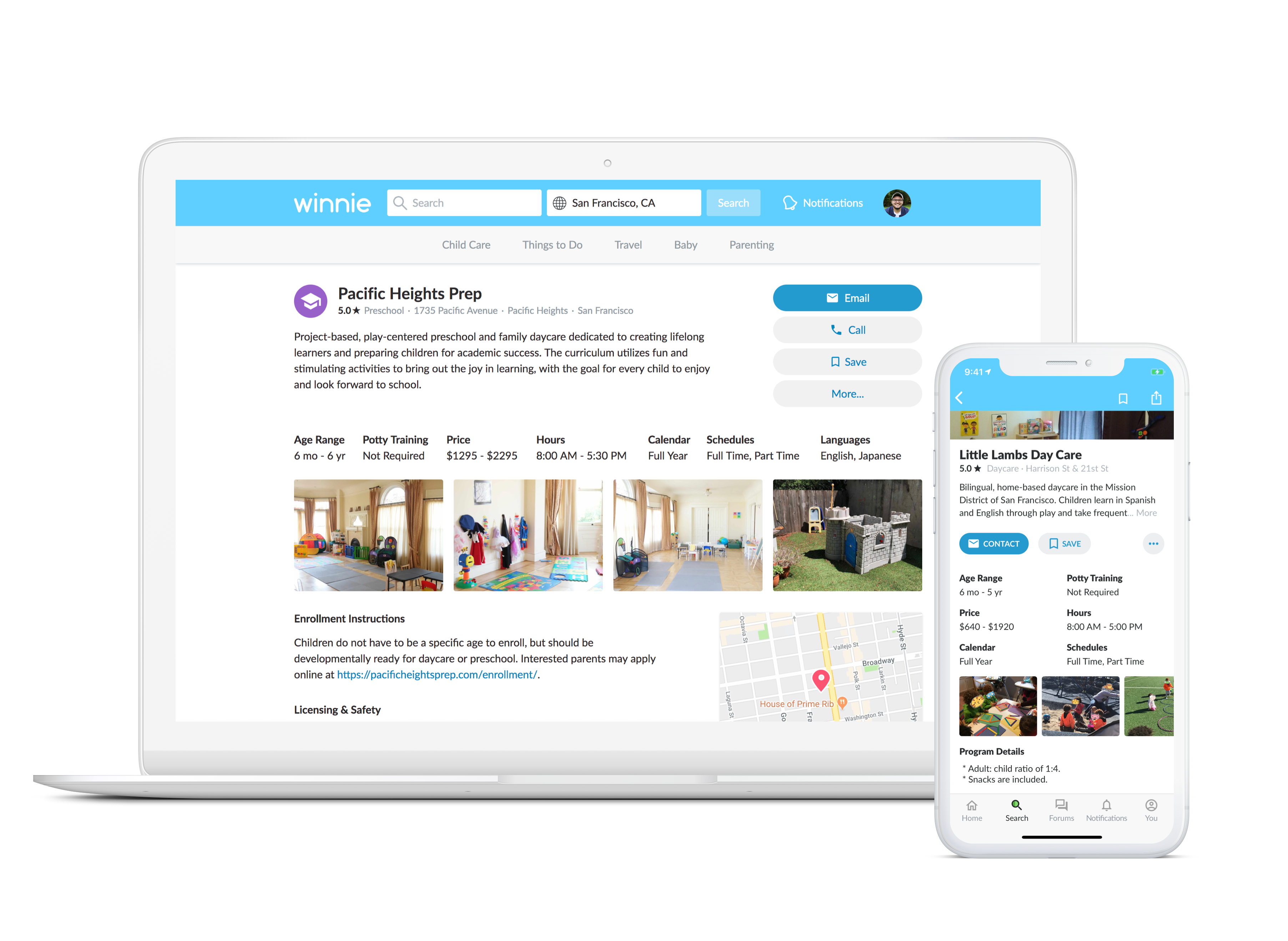
We’re constantly bringing providers online by giving them place pages for parents to find them. For providers whom have not claimed their place page, we attempt to keep these pages up to date for them. We do this by using the most recent data from external sources. As you can imagine, creating and updating thousands of place pages does not have to happen all at once. Heck, it can all happen in the background while I’m on my way home on BART. Creating and updating place pages means writing to our production tables. One or two writes to a table won’t sound the alarm. Thousands of writes happening all at once? We might want to plan ahead for that.
This is where RabbitMQ and Celery come into the picture. There’s a queue with items to be created or updated. There’s also a Celery task defined to consume from this queue and perform the write. To stay under our write capacities (and save money!), we’ve rate-limit how often this task can be run in a given time frame.
Decoupling data related process from our main application has made it easy to develop, deploy and maintain critical components. The benefits of message queues are there for the taking and it’s great to have your main application running when other parts of your system are down.
Conclusion
There’s a lot left to build and we’re just getting started. I hope this blog post provided you with insights on some of the technologies behind Winnie.
We’re always interested in chatting with people who actively use Winnie and are passionate about improving the lives of parents and children all over the world. If that sounds like you, shoot us a note at jobs@winnie.com.
Thank you Florence and Dylan for your feedback and contributions!